LIPO(Malherbe and Vayatis, 2017)는 우연히 발견한 전역 최적화(global optimization) 알고리즘인데 새로운 아이디어들이 쏟아져 나오는 세상이라 무감각해지긴 했지만 짚어볼 가치가 충분한 놈이다. Lipshitz 연속성 개념을 이용한 알고리즘인데 그 개념에 대해서는 Wikipedia에 잘 설명해 놓았더라. 이 놈도 Evolutionary Algorithm이나 Monte Carlo Search와 같이 추계적 탐색(stochastic search)을 사용한다. 즉, 미분을 사용하지 않는다. LIPO의 새로운 발상은 random하게 최적해를 탐색하되 좋은 놈만 골라서 sampling하다 보면 최적해를 빨리 찾을 수 있다는 것이다. 좋은 놈을 골라 내려면 기준이 필요한데 좋은 놈인지 알기는 어렵지만, 나쁜 놈은 쉽게 알 수 있다는 것이고 나쁜 놈들을 버리다 보면 좋은 놈만 남게 된다는 원리다. 그 기준이 되는 것이 Lipshitz upper bound(UB; 상한)이다. 이 기준을 적용하면 좋은 놈들의 목적함수 값만 알면 되기 때문에 목적함수 계산을 최소화할 수 있다는 것이다. 인공신경망과 같이 parameter 수가 많은 목적함수들은 목적함수 계산 비용도 어마무시하게 발생하기 때문에 이 놈이 그만한 가치가 있는 것이다.
Lipshitz Upper Bound
어떤 목적함수 f(x)가 있을 때 Lipshitz UB(L(x))는 모든 x에 대해서 f(x) 보다 크거나 같은 함수인데 아래의 조건을 만족하는 함수이다.
|f(x1) - f(x2)| <= k|x1 - x2| (단, k >= 0)
즉, L(x)는 아래와 같이 정의할 수 있다.
L(x) = f(x_i) + k|x - x_i| (단, i = 1, ..., t)
밑에 그림과 같이 L(x)는 k값에 따라 무수히 많은 놈이 있을 수 있지만 min L(x)인 k값이 존재한다는 것이고 min k 값을 특별히 Lipshitz 상수라 하더라. 참고로 Lipshitz UB를 만족하는 함수 f(x)를 Lipshitz 연속 함수라 하고 이런 함수들은 연속적이고 미분 가능하다. 또한 직관적으로 Lipshitz 상수는 f(x)의 최대 기울기(= 최대 미분값)와 일치함을 알수 있다. 역으로 연속 함수이고 미분 가능하다고 해서 Lipshitz UB가 항상 존재하는 것은 아니다. f(x) = x^2과 같이 이차 포물선 함수들이 대표적인 예이다. 하지만, 특정 구간에서는 Lipshitz UB가 존재할 수 있기 때문에 Lipshitz UB 개념은 불연속이고 미분 가능하지 않더라도 확장해서 사용할 수 있다. 그리고, 수치 미분을 사용할 경우에는 Lipshitz UB를 적용함으로써 함수의 연속성과 미분 가능성을 보장해 줄 수 있다.
LIPO Algorithm
알고리즘은 아래 그림으로 한 눈에 어떤 원리인지 알 수 있기 때문에 자세한 설명은 논문을 보거나 구글링해 보면 된다. 아래 그림은 전역 최대 값을 탐색할 때 random sampling한 x_i가 좋은 놈인지 Lipshitz UB로 판단할 수 있음을 보여준다. 즉, random하게 매번 sampling시 마다 Lipshitz UB(L(x))를 구할 수 있는데 max f(x) 값보다 min L(x) 값이 항상 크거나 같을 때만 좋은 놈이라고 보고 sampling을 하는 것이다. 그림과 같이 4번 sampling한 상태에서 다음 sampling한 놈이 좋은 놈이 되려면 현재 까지의 f(x) 최대값 보다 큰 구간에서만 x값을 sampling하면 되는 것이다. 빨간 선 아래에 있는 놈들은 모두 나쁜 놈이 되는 것이다. 즉, 좋은 놈 골라내기를 반복하다 보면 최소한의 목적함수 값만 계산하더라도 최대값을 찾아낼 수 있다는 것이 LIPO 알고리즘의 핵심 원리이다.

문제는 k값을 미리 알기 어렵다는 것인데 이 놈이 LIPO 알고리즘의 유일한 매개 변수(hyper parameter)가 된다. 그림에서는 k=2가 주어진 목적함수의 최대 기울기이자 L(x)가 최소가 되도록하는, 즉 Lipshitz 상수이다. k=10일 때와 비교해 보면 다음 번에 sampling할 구간이 굉장히 작다는 것을 알 수 있다. 또한, k값이 Lipshitz 상수보다 너무 작다면 아예 sampling을 하지 않게 되는 문제가 발생할 수도 있음을 알 수 있다. 즉, k값도 최적값이 존재하는데 L(x)가 최소가 되는 k값을 구하는 최적화 문제로 귀결된다. 원저자들의 논문에서는 adaptive LIPO(AdaLIPO) 알고리즘까지 제시하고 있는데 이미 sampling한 놈들의 최대 기울기를 k값으로 사용하면 된다는 것이 요지이다. 독립변수 x가 여러개 일때에도 각 변수 마다의 k값을 각각의 기울기를 이용해서 쉽게 구할 수 있다.
LIPO 테스트
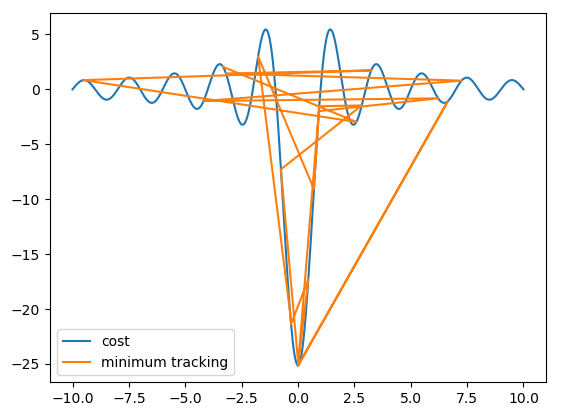
간단한 단변수 multi-modal 함수(f(x) = -(8/x)*sin(pi*x), 단, x = 1e-10 if |x| < 1e-10)의 최소값 찾기 테스트 결과를 아래 그림에 보였다. 참고로, AdaLIPO 보다는 단순한 adaptive LIPO 로직을 적용했다. 목적함수가 x=0 근처에서 기울기가 무한대가 되는 불연속 함수인데 0으로 나누기 오류가 발생할 수 있어서 1e-10값을 할당했다. k값은 목적함수의 기울기를 따라가기 때문에 무한대가 될 수 있는데 k값이 너무 커지면 Lipshitz UB를 사용하는 의미가 없어진다. 대략 1000을 넘지 않도록 해주면 된다. k값 자체를 엄밀하게 Quadratic Programming 등으로 최적화해서 사용할 수도 있는데 크게 의미 있어 보이진 않는다. random sampling을 사용하기 때문에 실제 목적 함수 값 계산 횟수(number of function evaluations; nfe)는 편자가 심하지만 Differential Evolution(DE) 알고리즘 보다는 확실히 적은 횟수만으로 준 최적값을 찾아낸다. 하지만 정확도까지 따지면 그닥 좋은 편은 아니다. 그래서 Quadratic Regression(QR)을 같이 사용한 결과가 아래 그림이다. 즉, exploration은 LIPO가 하고 exploitation은 QR이 하도록 했더니 좋은 결과가 나온 것이다.
맺음말
결론적으로, 최소한의 sampling으로 전역 최적해를 찾을 수 있다는 LIPO의 기본 발상은 매우 훌륭하다. Deep Learning에서도 최소의 data를 가지고 학습시키는 것이 중요한 연구 분야이다. 더불어 Lipshitz UB에 대해서 깊이 생각해 볼수 있었다. random search에서 sampling 문제를 인공신경망과 같은 일반적인 regression 문제에 대해서도 확장해서 생각해 볼 수 있는데, 이미 sampling한 data를 가지고 regression 목적 함수를 최적화 시키는 것에 대한 것이다. 즉, Lipshitz UB 개념을 학습에 사용되는 data들에도 적용할 수 있겠다는 것이다. training data들 중에도 좋은 놈이 있고 나쁜 놈이 있을 수 있는데, 이놈들을 걸러낼 수 있는 기준이 될 수 있겠다는 점이다. 아니면, 학습 data를 쉽게 얻을 수 있는 것은 아니기 때문에 data/parameter transformation을 통해 Lipshitz UB 조건을 충족하도록 할 수도 있겠다. 그래서 구글링했더니 GAN(Generative Adversarial Network)에서 gradient exploding 문제 때문에 Spectral Normalization을 적용해서 학습이 잘 되도록 했다는 연구 결과가 있더라. 아무튼 이 글을 읽은 사람들 중에 아이디어를 얻어서 연구에 활용해 보기를 기대한다.